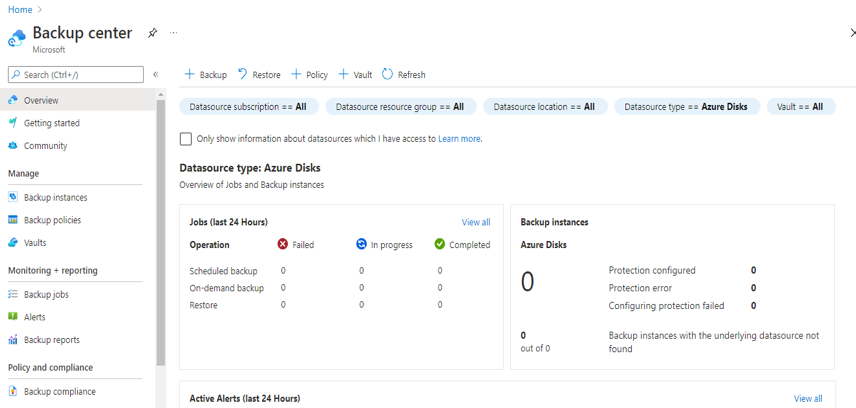
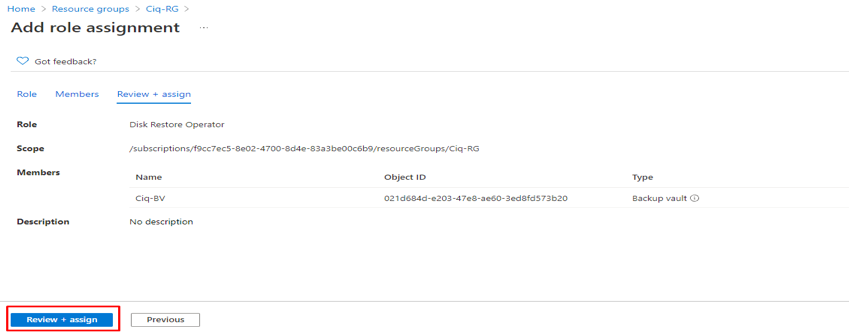
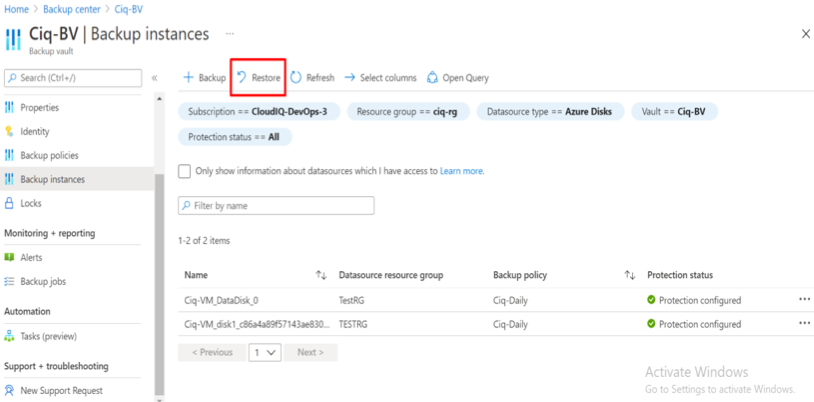
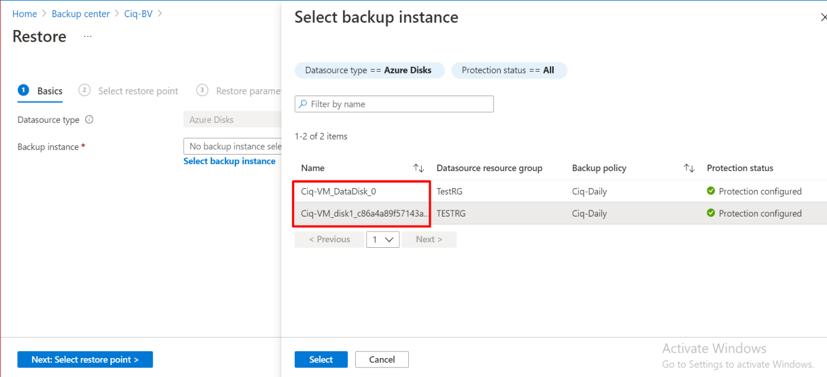
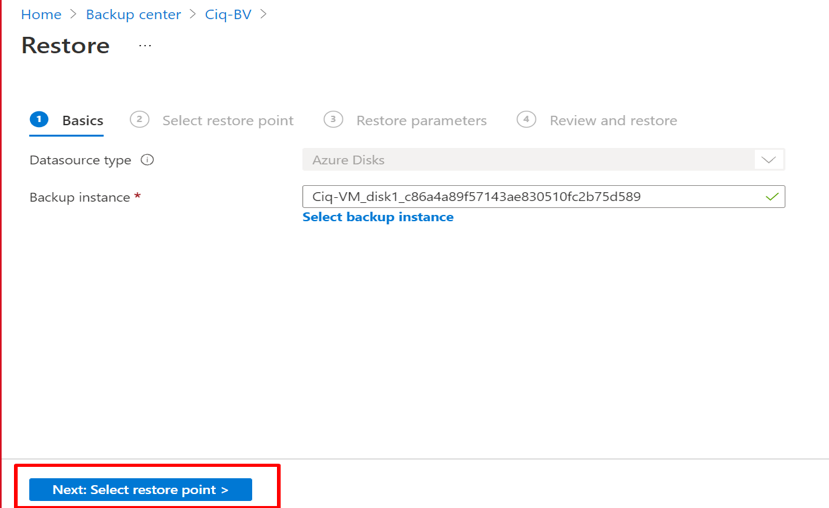
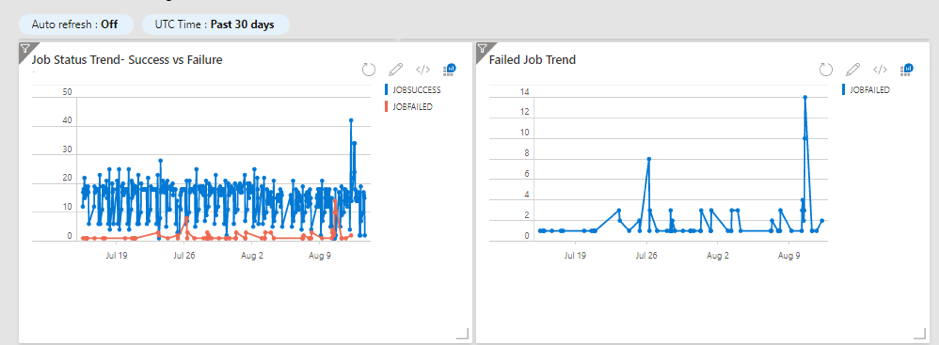
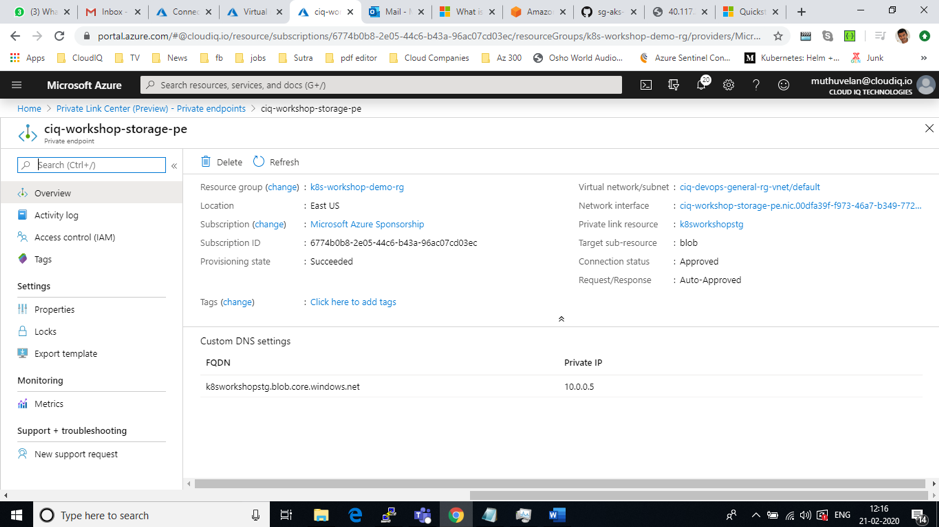
Cybersecurity is the number one concern for CEOs and is unanimously seen as the biggest threat in the coming years. Reports suggest that the damages from cyberattacks will to amount to $6 trillion annually by 2021.
While a lot of news coverage is given to malicious hackers and ransomware attacks, another crucial area of cyber protection is tightening the internal defenses with intelligent identity management. Keeping a tight control on who can get past your firewalls is vital for maintaining optimum security.
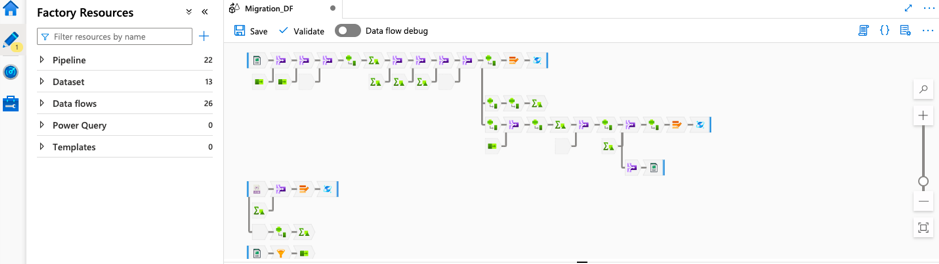
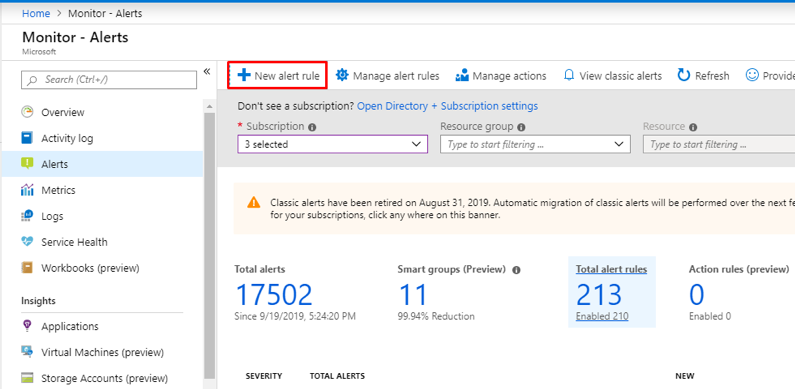
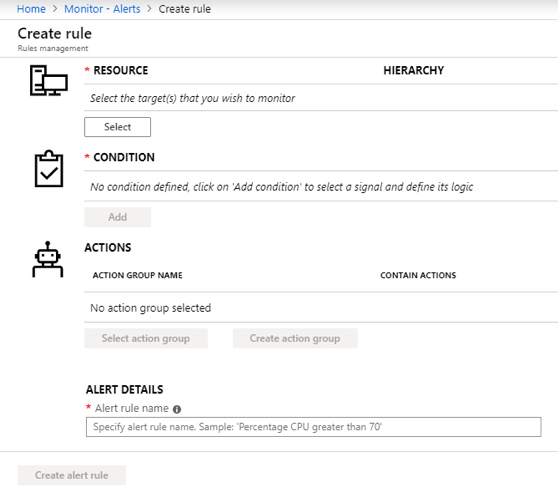
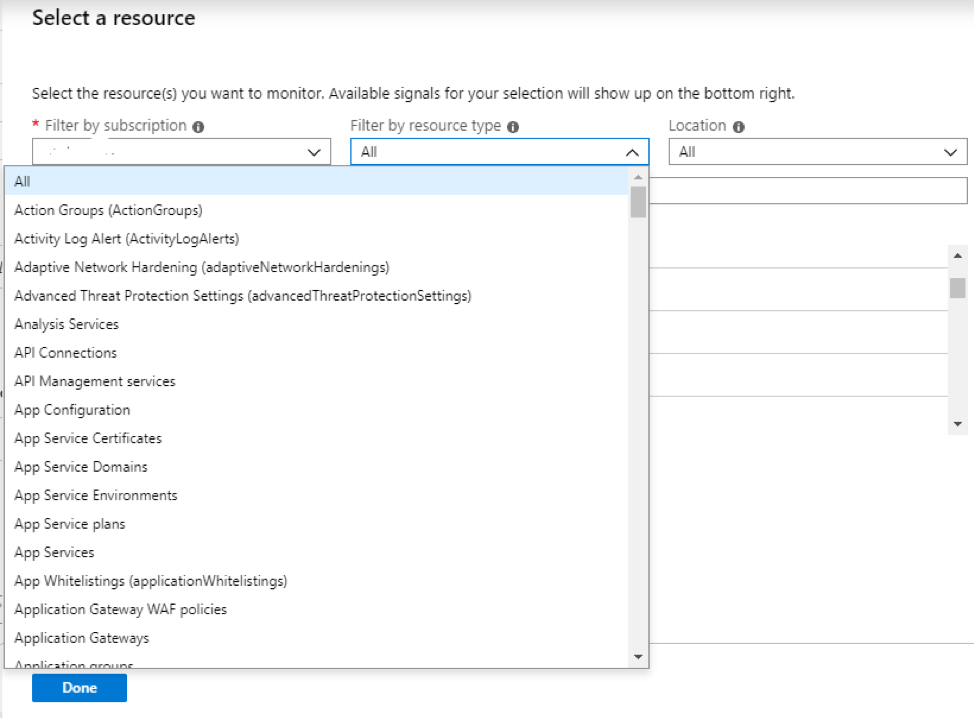
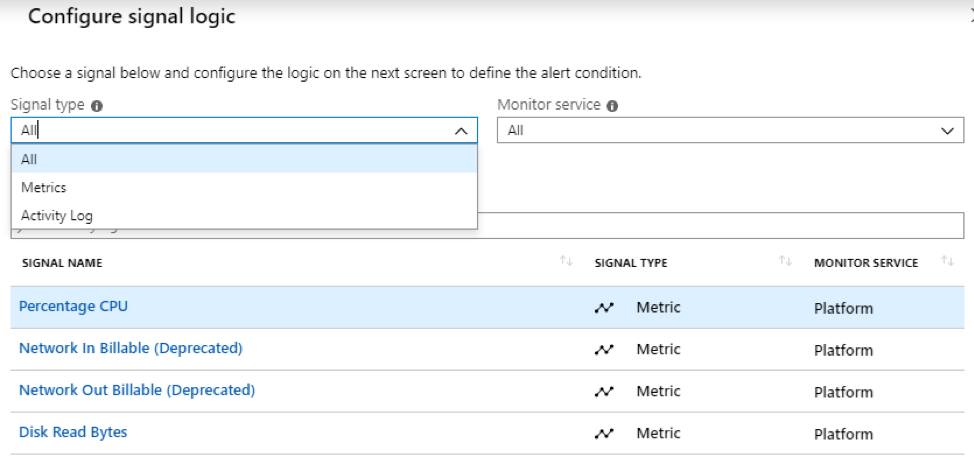
In this article we will review the comprehensive set of security tools available in Azure Cloud.
Azure Active Directory
Multi-Factor Authentication
Azure Multi-Factor Authentication (MFA) helps safeguard access to data and applications while maintaining simplicity for users. It provides additional security by requiring a second form of authentication and delivers strong authentication via a range of easy to use authentication methods. Users may or may not be challenged for MFA based on configuration decisions that an administrator makes.
The security of two-step verification lies in its layered approach. Compromising multiple authentication factors presents a significant challenge for attackers. Even if an attacker manages to learn the user’s password, it is useless without also having possession of the additional authentication method. It works by requiring two or more of the following authentication methods: Something you know (typically a password), Something you have (a trusted device that is not easily duplicated, like a phone), Something you are (biometrics)
Conditional Access policies
Conditional Access is the tool used by Azure Active Directory to bring signals together, to make decisions, and enforce organizational policies. Conditional Access policies at their simplest are if-then statements; if a user wants to access a resource, then they must complete an action. Example: A payroll manager wants to access the payroll application and is required to perform multi-factor authentication to access it.
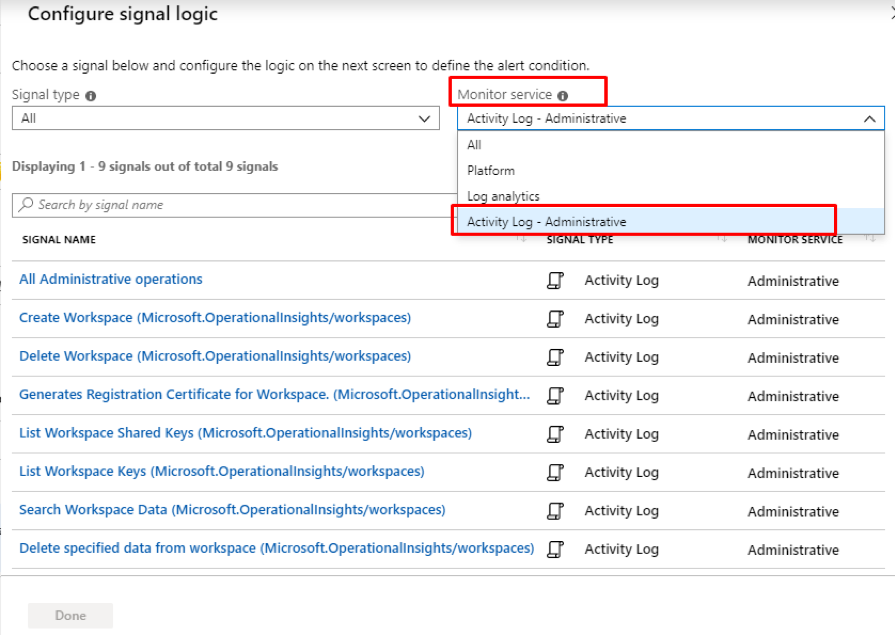
Azure AD identity protection
Identity Protection is a tool that allows organizations to accomplish three key tasks: Automate the detection and remediation of identity-based risks, Investigate risks using data in the portal, Export risk detection data to third-party utilities for further analysis. The signals generated by and fed to Identity Protection, can be further fed into tools like Conditional Access to make access decisions, or fed back to a security information and event management (SIEM) tool for further investigation based on your organization’s enforced policies.
Azure AD Privileged Identity Management
Privileged Identity Management provides time-based and approval-based role activation to mitigate the risks of excessive, unnecessary, or misused access permissions on resources that you care about. Here are some of the key features of Privileged Identity Management:
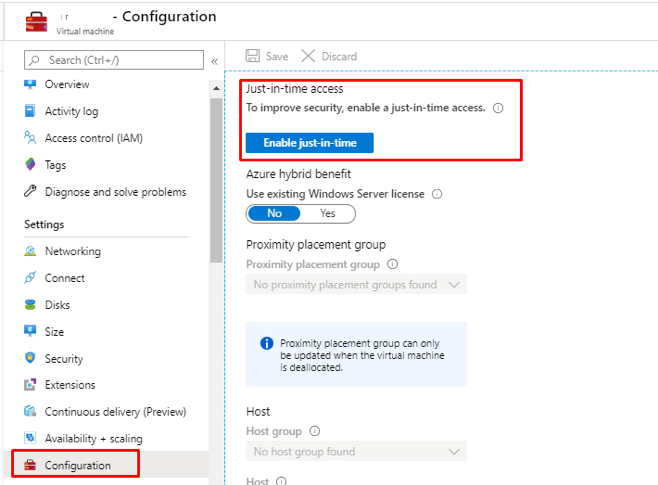
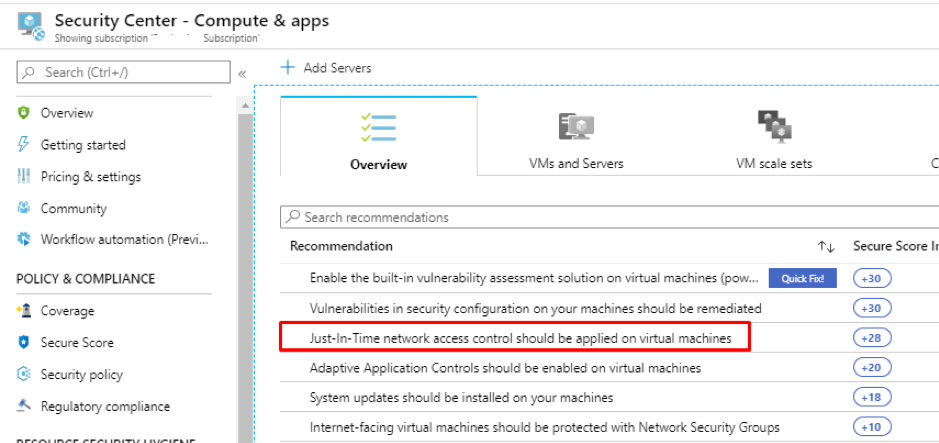
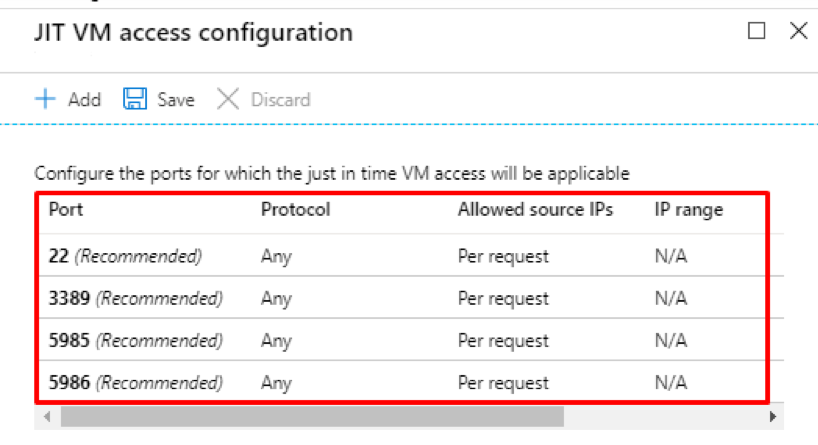
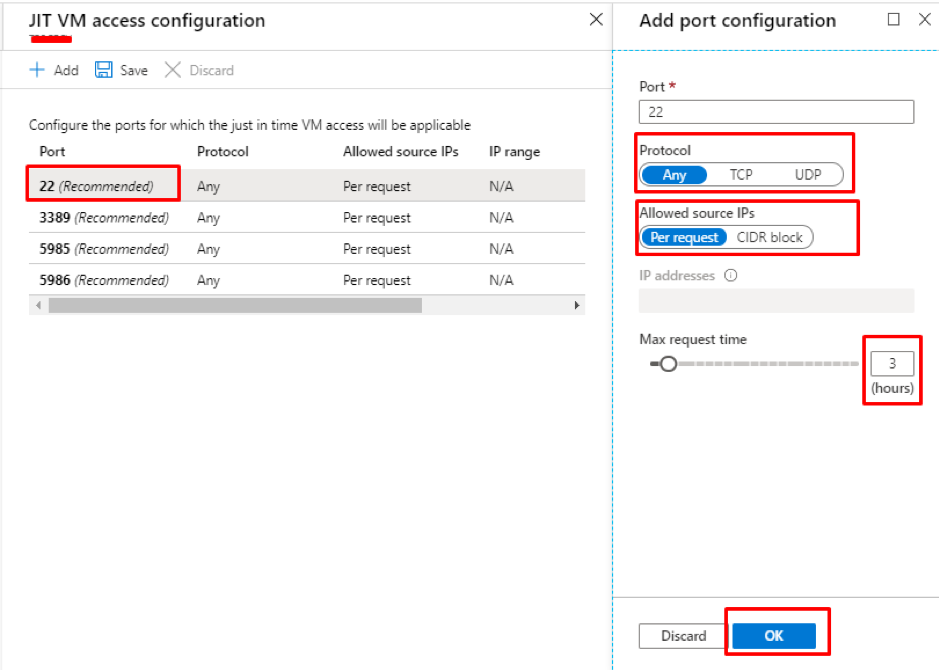
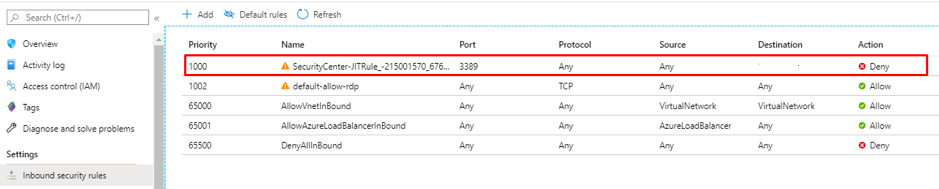
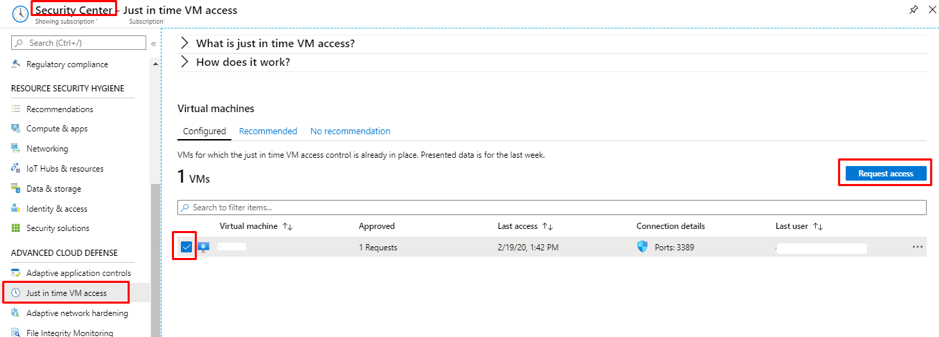
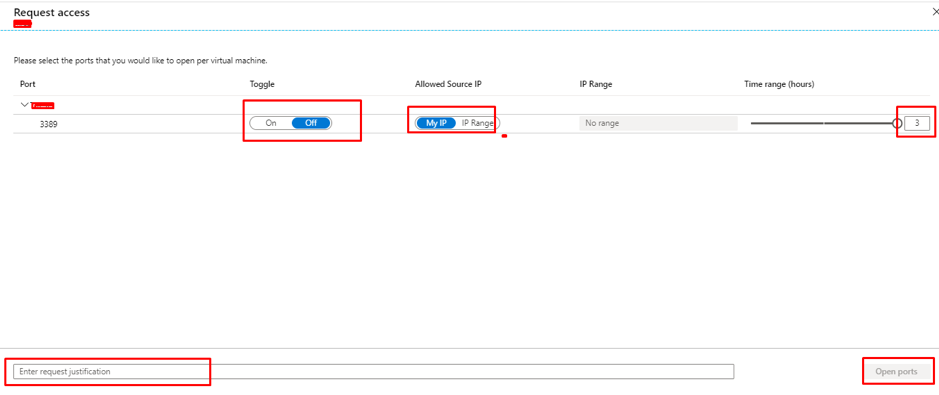
- Provide just-in-time privileged access to Azure AD and Azure resources
- Assign time-bound access to resources using start and end dates
- Require approval to activate privileged roles
- Enforce multi-factor authentication to activate any role
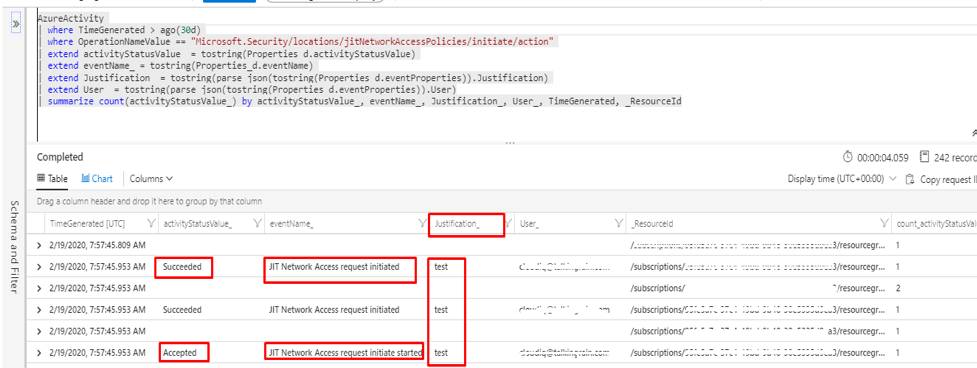
- Use justification to understand why users activate
- Get notifications when privileged roles are activated
- Conduct access reviews to ensure users still need roles
- Download audit history for internal or external audit
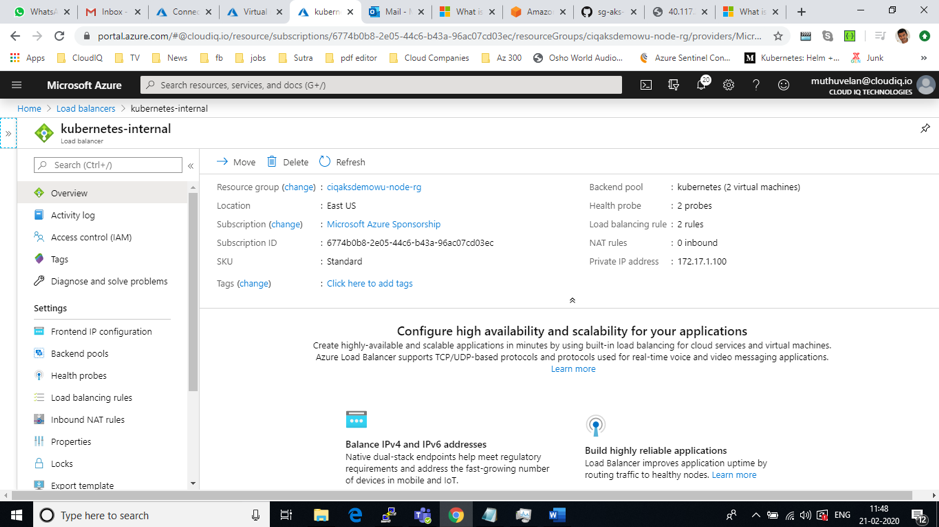
Network Security
Network Security Groups (NSGs)
Network security group security rules are evaluated by priority using the 5-tuple information (source, source port, destination, destination port, and protocol) to allow or deny the traffic. A flow record is created for existing connections. Communication is allowed or denied based on the connection state of the flow record. The flow record allows a network security group to be stateful. If you specify an outbound security rule to any address over port 80, for example, it’s not necessary to specify an inbound security rule for the response to the outbound traffic. You only need to specify an inbound security rule if communication is initiated externally. The opposite is also true. If inbound traffic is allowed over a port, it’s not necessary to specify an outbound security rule to respond to traffic over the port. Existing connections may not be interrupted when you remove a security rule that enabled the flow. Traffic flows are interrupted when connections are stopped, and no traffic is flowing in either direction, for at least a few minutes.
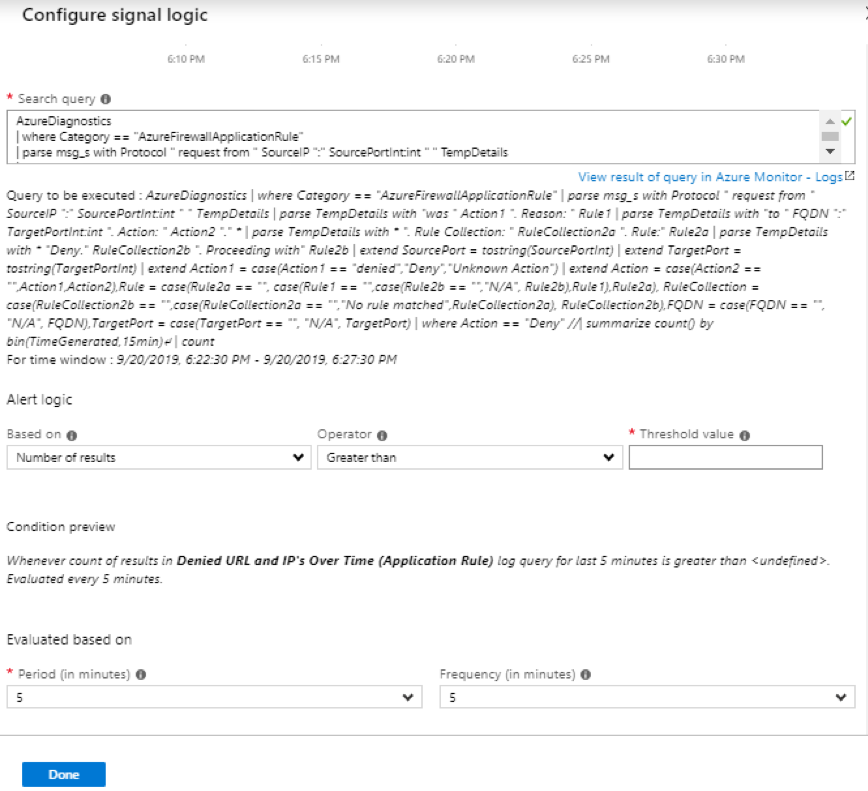
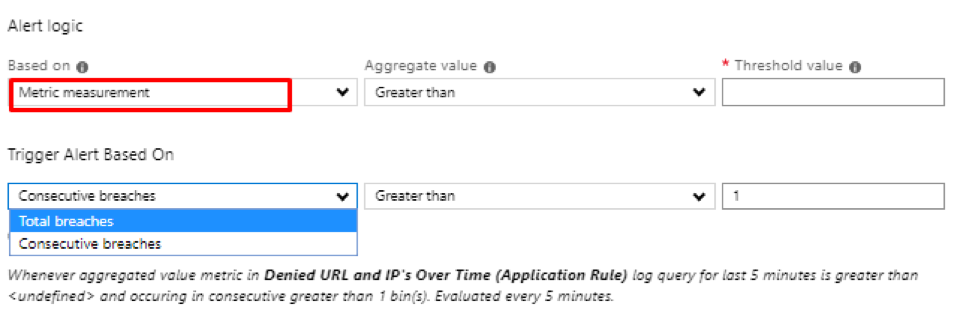
Azure Firewall
With Azure Firewall, you can configure – Application rules that define fully qualified domain names (FQDNs) that can be accessed from a subnet and Network rules that define source address, protocol, destination port, and destination address. Network traffic is subjected to the configured firewall rules when you route your network traffic to the firewall as the subnet default gateway.
Application security groups
Application security groups enable you to configure network security as a natural extension of an application’s structure, allowing you to group virtual machines and define network security policies based on those groups. You can reuse your security policy at scale without manual maintenance of explicit IP addresses. The platform handles the complexity of explicit IP addresses and multiple rule sets, allowing you to focus on your business logic.
Resource management security
Azure resource locks
As an administrator, you may need to lock a subscription, resource group, or resource to prevent other users in your organization from accidentally deleting or modifying critical resources. You can set the lock level to CanNotDelete or ReadOnly. In the portal, the locks are called Delete and Read-only, respectively. CanNotDelete means authorized users can still read and modify a resource, but they can’t delete the resource. ReadOnly means authorized users can read a resource, but they can’t delete or update the resource. Applying this lock is similar to restricting all authorized users to the permissions granted by the Reader role.
Azure policies
Azure Policy is a service in Azure that you use to create, assign, and manage policies. These policies enforce different rules and effects over your resources, so those resources stay compliant with your corporate standards and service level agreements. Azure Policy meets this need by evaluating your resources for non-compliance with assigned policies. All data stored by Azure Policy is encrypted at rest. For example, you can have a policy to allow only a certain SKU size of virtual machines in your environment. Once this policy is implemented, new and existing resources are evaluated for compliance.
Custom RBAC roles
Granting permission using custom Azure AD roles is a two-step process that involves creating a custom role definition and then assigning it using a role assignment. A custom role definition is a collection of permissions that you add from a preset list. These permissions are the same permissions used in the built-in roles.
Once youíve created your role definition, you can assign it to a user by creating a role assignment. A role assignment grants the user the permissions in a role definition at a specified scope. This two-step process allows you to create a single role definition and assign it many times at different scopes. A scope defines the set of Azure AD resources the role member has access to.
Encryption for data at rest
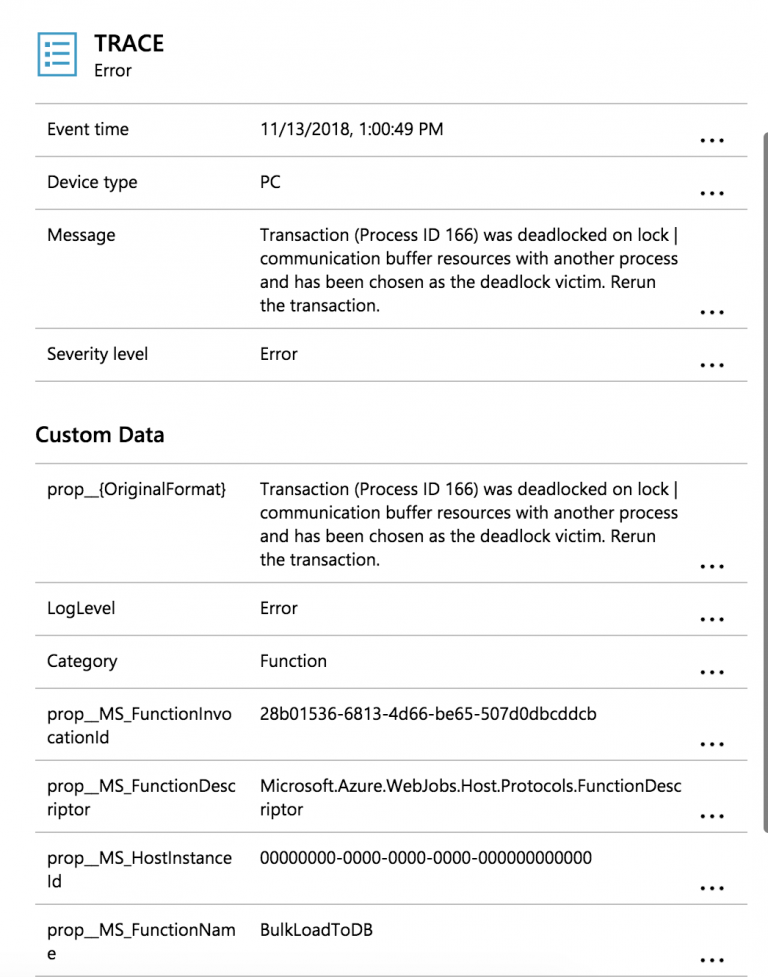
Azure SQL Database Always Encrypted
Always Encrypted is a new data encryption technology in Azure SQL Database and SQL Server that helps protect sensitive data at rest on the server during movement between client and server, and while the data is in use, ensuring that sensitive data never appears as plaintext inside the database system. After you encrypt data, only client applications or app servers that have access to the keys can access plaintext data.
Implement database encryption
Transparent data encryption (TDE) helps protect Azure SQL Database, Azure SQL Managed Instance, and Azure Data Warehouse against the threat of malicious offline activity by encrypting data at rest. It performs real-time encryption and decryption of the database, associated backups, and transaction log files at rest without requiring changes to the application. By default, TDE is enabled for all newly deployed Azure SQL databases.
Implement Storage Service Encryption
Data in Azure Storage is encrypted and decrypted transparently using 256-bit AES encryption, one of the strongest block ciphers available, and is FIPS 140-2 compliant. Azure Storage encryption is similar to BitLocker encryption on Windows.
Azure Storage encryption is enabled for all new storage accounts, including both Resource Manager and classic storage accounts. Azure Storage encryption cannot be disabled. Because your data is secured by default, you don’t need to modify your code or applications to take advantage of Azure Storage encryption.
Implement disk encryption
Azure Disk Encryption helps protect and safeguard your data to meet your organizational security and compliance commitments. It uses the Bitlocker feature of Windows to provide volume encryption for the OS and data disks of Azure virtual machines (VMs), and is integrated with Azure Key Vault to help you control and manage the disk encryption keys and secrets.
Configure SSL/TLS certs
If you purchase an App Service Certificate from Azure, Azure manages the following tasks: Takes care of the purchase process from GoDaddy, Performs domain verification of the certificate, Maintains the certificate in Azure Key Vault, Manages certificate renewal (see Renew certificate), Synchronize the certificate automatically with the imported copies in App Service apps.
Manage access to Key Vault
Azure Key Vault is a cloud service that safeguards encryption keys and secrets like certificates, connection strings, and passwords. Because this data is sensitive and business-critical, you need to secure access to your key vaults by allowing only authorized applications and users.
Access to a key vault is controlled through two interfaces: the management plane and the data plane. The management plane is where you manage Key Vault itself. Operations in this plane include creating and deleting key vaults, retrieving Key Vault properties, and updating access policies. The data plane is where you work with the data stored in a key vault. You can add, delete, and modify keys, secrets, and certificates.
To access a key vault in either plane, all callers (users or applications) must have proper authentication and authorization. Authentication establishes the identity of the caller. Authorization determines which operations the caller can execute.
Both planes use Azure Active Directory (Azure AD) for authentication. For authorization, the management plane uses role-based access control (RBAC), and the data plane uses a Key Vault access policy.