RABBITMQ
What is RabbitMQ?
RabbitMQ is an open source message broker software. It accepts messages from producers, and delivers them to consumers. It acts like a middleman which can be used to reduce loads and delivery times taken by web application servers
Features of RabbitMQ:
RabbitMQ is an open source message broker software. It accepts messages from producers, and delivers them to consumers. It acts like a middleman which can be used to reduce loads and delivery times taken by web application servers
- Robust messaging for building applications in a distributed manner.
- Easy to use
- Runs on all major Operating Systems.
- Supports a huge number of developer platforms
- Supports multiple messaging protocols, message queuing, delivery acknowledgement, flexible routing to queues, multiple exchange type.
- Open source and commercially supported
How RabbitMQ Works?
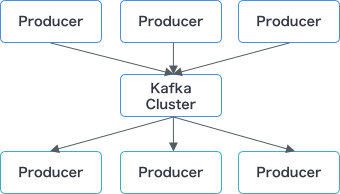
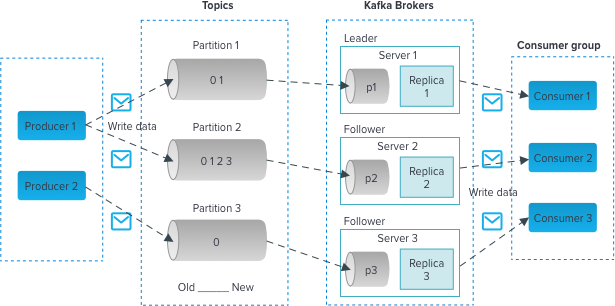
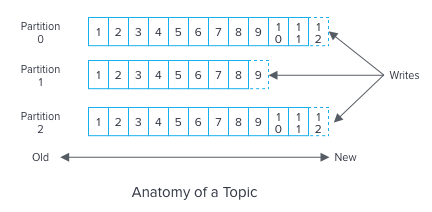
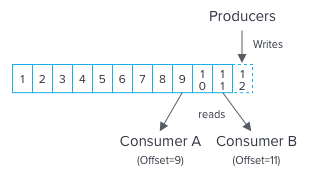
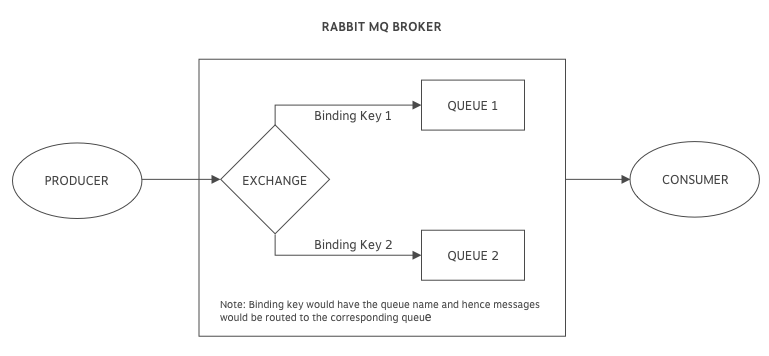
The Producer sends messages to an exchange. An exchange is responsible for the routing of the messages to the different queues. An exchange accepts messages from the producer application and routes them to message queues with the help of bindings and routing keys. A binding is a key between a queue and an exchange. Then consumers receive messages from the queue.
Prerequisites:
- RabbitMQ
- Python
How to Send and Receive a message using RABBITMQ?
Send a Message using RabbitMQ:
Following Program send.py will send a single message to the queue.
Step 1: To Establish a connection with RabbitMQ server.
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
Step 2: To Create a hello queue to which the message will be delivered:
channel.queue_declare(queue='hello')
Step 3: Publish the message and mention the exchange details and queue name in the exchange and routing key params to which queue the message should go.
channel.basic_publish(exchange='', routing_key='hello', body='Hello RabbitMQ!')
print(" [x] Sent 'Hello RabbitMQ!'")
Step 4: closing a connection to make sure the network buffers were flushed and our message was actually delivered to RabbitMQ
connection.close()
Recieve a message using RabbitMQ:
Following Program recieve.py will send a single message to the queue.
Step 1: It works by subscribing a callbackfunction to a queue. Whenever receiving a message, this callback function is called by the Pika library. Following function will print on the screen the contents of the message.
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
Step 2:Next, need to tell RabbitMQ that this particular callback function should receive messages from our hello queue:
channel.basic_consume(
queue='hello', on_message_callback=callback, auto_ack=True)
Step 3:And finally, Enter a never-ending loop that waits for data and runs callbacks whenever necessary.
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
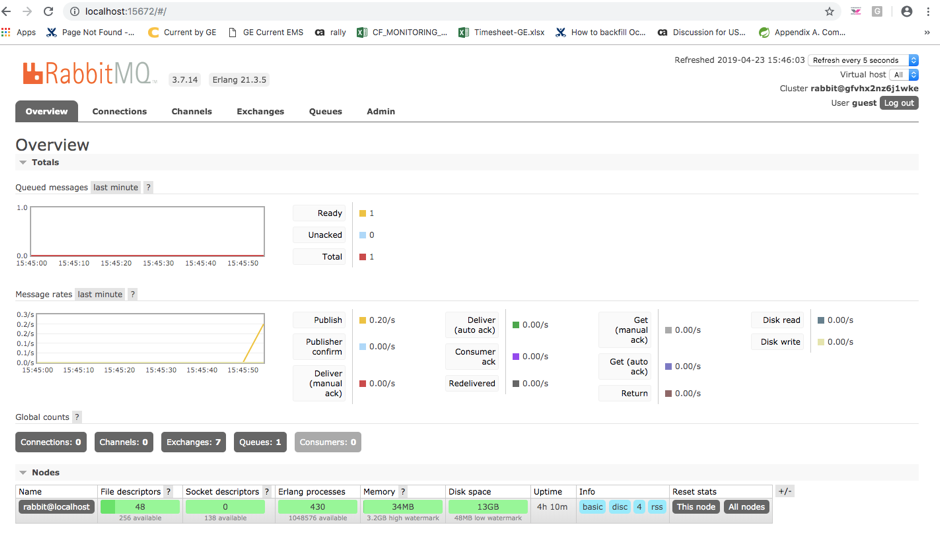
Step 4:Open terminal. Run the Send.py The producer program will stop after every run: python send.py [x] Sent ‘Hello RabbitMQ!’ We can go to the web browser and hit the URL http://localhost:15672/, and see the count of the message sent as shown below in the dashboard:
Step 5: Open terminal. Run the receive.py program.
python receive.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received ‘Hello RabbitMQ!’
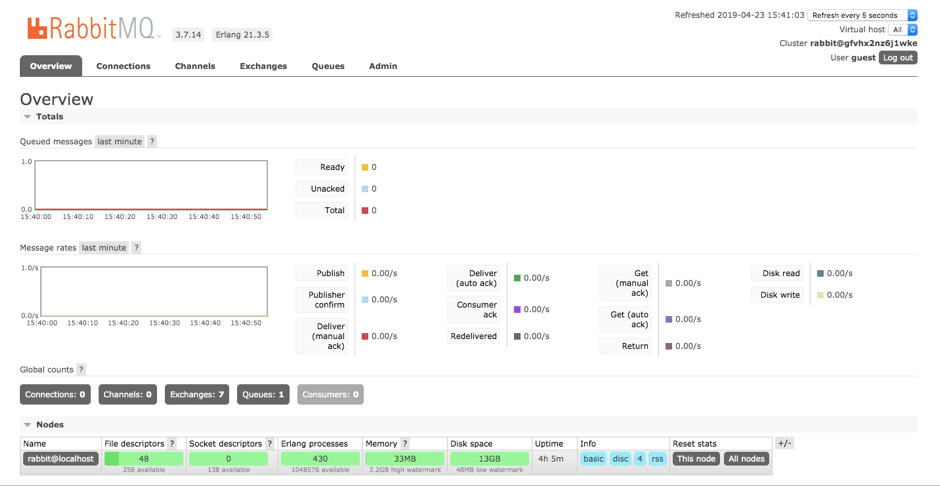
If ready and total count is zero in the dashboard, then confirm the messages are received by consumer.
Note: Continuously send a message through RabbitMQ. As noticed, the receive.py program doesn’t exit. It will stay ready to receive further messages, and may be interrupted with Ctrl-C.