
ELK – Elasticsearch, Logstash & Kibana
Introduction
As more and more IT infrastructures move to public clouds such as Amazon Web Services, Microsoft Azure, and Google Cloud, public cloud security tools, and logging platforms are both becoming more and more critical.
The ELK Stack is popular because it fulfills a specific need in the log management and log analysis space. In cloud-based infrastructures, consolidating log outputs to a central location from different sources like web servers, mail servers, database servers, network appliances can be particularly useful. This is especially true when trying to make better data-informed decisions. The ELK stack simplifies searching and analyzing data by providing insights in real-time from the log data.
It is common to run the full ELK stack, not each individual component separately. Each of these services play a important role and in order to perform under high demand it is more advantageous to deploy each service on its own server.
Why ELK?
• Rapid on-premise (or cloud) installation and easy to deploy
• Scales vertically and horizontally
• Easy and various APIs to use
• Ease of writing queries, a lot easier then writing a MapReduce job
• Availability of libraries for most programming/scripting languages
• Elastic offers a host of language clients for Elasticsearch, including Ruby, Python, PHP,
Perl, .NET, Java, and Javascript, and more
• Tools availability
• It’s free (open source), and it’s quick
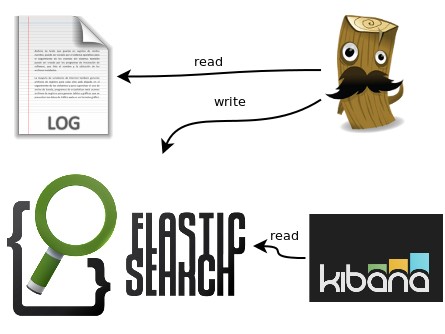
ELK Stack is used for log collection, indexing and visualization of the collected log data, we can collect any type of logs (windows event logs, http logs , apache server logs etc. ) in the ELK Stack as per configuration.
Logstash:
Logstash is a light-weight, open-source, server-side data processing pipeline that allows you to collect data from a variety of sources, transform it on the fly, and send it to your desired destination. It is most often used as a data pipeline for Elasticsearch, an open-source analytics and search engine. Because of its tight integration with Elasticsearch, powerful log processing capabilities, and over 200 pre-built open-source plugins that can help you easily index your data, Logstash is a popular choice for loading data into Elasticsearch.
Logstash allows you to easily ingest unstructured data from a variety of data sources including system logs, website logs, and application server logs. Logstash offers pre-built filters, so you can readily transform common data types, index them in Elasticsearch, and start querying without having to build custom data transformation pipelines.
The server component of Logstash processes incoming logs. In other words, Logstash collects, parses, and enriches logs before indexing them into Elasticsearch.
It is the pipeline which collects log data and pushes the collected data to the Elasticsearch.
Logstash Input Plugins
• Stdin – Reads events from standard input
• File – Streams events from files (similar to “tail -0F”)
• Syslog – Reads syslog messages as events
• Eventlog – Pulls events from the Windows Event Log
• Imap – read mail from an IMAP server
• Rss – captures the output of command line tools as an event
• Snmptrap – creates events based on SNMP trap messages
• Twitter – Reads events from the Twitter Streaming API
• Irc – reads events from an IRC server
• Exec – Captures the output of a shell command as an event
• Elasticsearch – Reads query results from an Elasticsearch cluster
Logstash Filter Plugins
• grok – parses unstructured event data into fields
• Mutate – performs mutations on fields
• Geoip – adds geographical information about an IP address
• Date – parse dates from fields to use as the Logstash timestamp for
an event
• Cidr – checks IP addresses against a list of network blocks
• Drop – drops all events
Logstash Output Plugins
• Stdout – prints events to the standard output
• Csv – write events to disk in a delimited format
• Email – sends email to a specified address when output is received
• Elasticsearch – stores logs in Elasticsearch
• Exec – runs a command for a matching event
• File – writes events to files on disk
• mongoDB – writes events to MongoDB
• Redmine – creates tickets using the Redmine API
Elasticsearch
Elasticsearch is the Data storage and indexing part of the ELK Stack. It stores data and indexes it.
It is also a Search engine based on Lucene and provides a distributed search engine with an HTTP web interface and schema-free JSON documents.
The distributed nature of Elasticsearch enables it to process large volumes of data in parallel, quickly finding the best matches for your queries. Elasticsearch operations such as reading or writing data usually take less than a second to complete. This lets you use Elasticsearch for near real-time use cases such as application monitoring and anomaly detection.
An index is like a ‘database’ in a relational database. It has a mapping which defines multiple types. We can think of an index as a type of data organization mechanism, allowing the user to partition data a certain way.
Other key concepts of Elasticsearch are replicas and shards, the mechanism Elasticsearch uses to distribute data around the cluster. Elasticsearch implements a clustered architecture that uses sharding to distribute data across multiple nodes, and replication to provide high availability.
The index is a logical namespace which maps to one or more primary shards and can have zero or more replica shards. A shard is a Lucene index and an Elasticsearch index is a collection of shards. The application talks to an index, and Elasticsearch routes the requests to the appropriate shards.
Kibana:
Kibana is the visualization web interface through which we can visualize the indexed log data. Kibana is an open-source data visualization and exploration tool used for log and time-series analytics, application monitoring, and operational intelligence use cases. It offers powerful and easy-to-use features such as histograms, line graphs, pie charts, heat maps, and built-in geospatial support.