What is Jenkins?
Jenkins is an open source automation tool written in Java with plugins built for Continuous Integration purpose. Jenkins is used to build and test your software projects continuously making it easier for developers to integrate changes to the project, and making it easier for users to obtain a fresh build. It also allows you to continuously deliver your software by integrating with a large number of testing and deployment technologies.
With Jenkins, organizations can accelerate the software development process through automation. Jenkins integrates development life-cycle processes of all kinds, including build, document, test, package, stage, deploy, static analysis and much more.
Jenkins achieves Continuous Integration with the help of plugins. Plugins allows the integration of Various DevOps stages. If you want to integrate a particular tool, you need to install the plugins for that tool. For example: Git, Maven 2 project, Amazon EC2, HTML publisher etc.
Advantages of Jenkins include:
- It is an open source tool with great community support.
- It is easy to install.
- It has 1000+ plugins to ease your work. If a plugin does not exist, you can code it and share with the community.
- It is free of cost.
- It is built with Java and hence, it is portable to all the major platforms
What is Continuous Integration?
Continuous Integration is a development practice in which the developers are required to commit changes to the source code in a shared repository several times a day or more frequently. Every commit made in the repository is then built. This allows the teams to detect the problems early. Apart from this, depending on the Continuous Integration tool, there are several other functions like deploying the build application on the test server, providing the concerned teams with the build and test results etc.
Continuous Integration with Jenkins
- First, a developer commits the code to the source code repository. Meanwhile, the Jenkins server checks the repository at regular intervals for changes.
- Soon after a commit occurs, the Jenkins server detects the changes that have occurred in the source code repository. Jenkins will pull those changes and will start preparing a new build.
- If the build fails, then the concerned team will be notified.
- If built is successful, then Jenkins deploys the built in the test server.
- After testing, Jenkins generates a feedback and then notifies the developers about the build and test results.
- It will continue to check the source code repository for changes made in the source code and the whole process keeps on repeating.
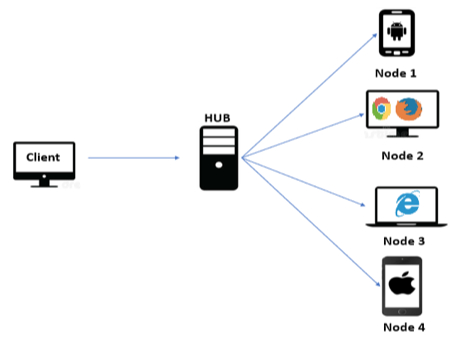
Jenkins Distributed Architecture
Jenkins uses a Master-Slave architecture to manage distributed builds. In this architecture, Master and Slave communicate through TCP/IP protocol.
Jenkins Master
Your main Jenkins server is the Master. The Master’s job is to handle:
- Scheduling build jobs.
- Dispatching builds to the slaves for the actual execution.
- Monitor the slaves (possibly taking them online and offline as required).
- Recording and presenting the build results.
- A Master instance of Jenkins can also execute build jobs directly.
Jenkins Slave
A Slave is a Java executable that runs on a remote machine. Following are the characteristics of Jenkins Slaves:
- It hears requests from the Jenkins Master instance.
- Slaves can run on a variety of operating systems.
- The job of a Slave is to do as they are told to, which involves executing build jobs dispatched by the Master.
- You can configure a project to always run on a particular Slave machine, or a particular type of Slave machine, or simply let Jenkins pick the next available Slave.
What is a Jenkins pipeline?
A pipeline is a collection of jobs that brings the software from version control into the hands of the end users by using automation tools. It is a feature used to incorporate continuous delivery in our software development workflow.
Over the years, there have been multiple Jenkins pipeline releases including, Jenkins Build flow, Jenkins Build Pipeline plugin, Jenkins Workflow, etc. What are the key features of these plugins?
- They represent multiple Jenkins jobs as one whole workflow in the form of a pipeline.
- What do these pipelines do? These pipelines are a collection of Jenkins jobs which trigger each other in a specified sequence.
Lets look at an example. Suppose I’m developing a small application on Jenkins and I want to build, test and deploy it. To do this, I will allot 3 jobs to perform each process. So, job1 would be for build, job2 would perform tests and job3 for deployment. I can use the Jenkins build pipeline plugin to perform this task. After creating three jobs and chaining them in a sequence, the build plugin will run these jobs as a pipeline.
This approach is effective for deploying small applications. But what happens when there are complex pipelines with several processes (build, test, unit test, integration test, pre-deploy, deploy, monitor) running 100’s of jobs?
The maintenance cost for such a complex pipeline is huge and increases with the number of processes. It also becomes tedious to build and manage such a vast number of jobs. To overcome this issue, a new feature called Jenkins Pipeline Project was introduced.
The key feature of this pipeline is to define the entire deployment flow through code. What does this mean? It means that all the standard jobs defined by Jenkins are manually written as one whole script and they can be stored in a version control system. It basically follows the ‘pipeline as code’ discipline. Instead of building several jobs for each phase, you can now code the entire workflow and put it in a Jenkinsfile. Below is a list of reasons why you should use the Jenkins Pipeline.
Jenkins Pipeline Advantages
- It models simple to complex pipelines as code by using Groovy DSL (Domain Specific Language)
- The code is stored in a text file called the Jenkinsfile which can be checked into a SCM (Source Code Management)
- Improves user interface by incorporating user input within the pipeline
- It is durable in terms of unplanned restart of the Jenkins master
- It can restart from saved checkpoints
- It supports complex pipelines by incorporating conditional loops, fork or join operations and allowing tasks to be performed in parallel
- It can integrate with several other plugins
What is a Jenkinsfile?
A Jenkinsfile is a text file that stores the entire workflow as code and it can be checked into a SCM on your local system. How is this advantageous? This enables the developers to access, edit and check the code at all times.
The Jenkinsfile is written using the Groovy DSL and it can be created through a text/groovy editor or through the configuration page on the Jenkins instance. It is written based on two syntaxes, namely:
- Declarative pipeline syntax
- Scripted pipeline syntax
Declarative pipeline is a relatively new feature that supports the pipeline as code concept. It makes the pipeline code easier to read and write. This code is written in a Jenkinsfile which can be checked into a source control management system such as Git.
Whereas, the scripted pipeline is a traditional way of writing the code. In this pipeline, the Jenkinsfile is written on the Jenkins UI instance. Though both these pipelines are based on the groovy DSL, the scripted pipeline uses stricter groovy based syntaxes because it was the first pipeline to be built on the groovy foundation. Since this Groovy script was not typically desirable to all the users, the declarative pipeline was introduced to offer a simpler and more optioned Groovy syntax.
The declarative pipeline is defined within a block labelled ‘pipeline’ whereas the scripted pipeline is defined within a ‘node’
An example Jenkinsfile looks like this:
pipeline {
environment {
BUILD_SCRIPTS_GIT="http://10.100.100.10:7990/scm/~myname/mypipeline.git"
BUILD_SCRIPTS='mypipeline'
BUILD_HOME='/var/lib/jenkins/workspace'
}
agent any
stages {
stage('Checkout: Code') {
steps {
sh "mkdir -p $WORKSPACE/repo;\
git config --global user.email '[email protected]';\
git config --global user.name 'myname';\
git config --global push.default simple;\
git clone $BUILD_SCRIPTS_GIT repo/$BUILD_SCRIPTS"
sh "chmod -R +x $WORKSPACE/repo/$BUILD_SCRIPTS"
}
}
stage('Yum: Updates') {
steps {
sh "sudo chmod +x $WORKSPACE/repo/$BUILD_SCRIPTS/scripts/update.sh"
sh "sudo $WORKSPACE/repo/$BUILD_SCRIPTS/scripts/update.sh"
}
}
}
post {
always {
cleanWs()
}
}
}
The above Jenkins file does the following.
- sets up environment variables
- pulls data down from a git repo
- sets it up in a Jenkins workspace
- runs a script under scripts/
- once completes by cleaning up the workspace (successful or not)
Pipeline concepts
This is a user defined block which contains all the processes such as build, test, deploy, etc. It is a collection of all the stages in a Jenkinsfile. All the stages and steps are defined within this block. It is the key block for a declarative pipeline syntax.
A node is a machine that executes an entire workflow. It is a key part of the scripted pipeline syntax.
There are various mandatory sections which are common to both the declarative and scripted pipelines, such as stages, agent and steps that must be defined within the pipeline. These are explained below:
An agent is a directive that can run multiple builds with only one instance of Jenkins. This feature helps to distribute the workload to different agents and execute several projects within a single Jenkins instance. It instructs Jenkins to allocate an executor for the builds.
A single agent can be specified for an entire pipeline or specific agents can be allotted to execute each stage within a pipeline. Few of the parameters used with agents are:
Runs the pipeline/ stage on any available agent.
This parameter is applied at the root of the pipeline and it indicates that there is no global agent for the entire pipeline and each stage must specify its own agent.
Executes the pipeline/stage on the labelled agent.
This parameter uses docker container as an execution environment for the pipeline or a specific stage. In the below example I’m using docker to pull an ubuntu image. This image can now be used as an execution environment to run multiple commands.
This block contains all the work that needs to be carried out. The work is specified in the form of stages. There can be more than one stage within this directive. Each stage performs a specific task. In the following example, I’ve created multiple stages, each performing a specific task.
A series of steps can be defined within a stage block. These steps are carried out in sequence to execute a stage. There must be at least one step within a steps directive. In the following example I’ve implemented an echo command within the build stage. This command is executed as a part of the ‘Build’ stage.