Getting started with Azure Databricks, the Apache Spark based analytics service
Databricks is a web-based platform for working with Apache Spark, that provides automated cluster management and IPython-style notebooks. To understand the basics of Apache Spark, refer to our earlier blog on how Apache Spark works
Databricks is currently available on Microsoft Azure and Amazon AWS. In this blog, we will look at some of the components in Azure Databricks.
1. Workspace
A Databricks Workspace is an environment for accessing all Databricks assets. The Workspace organizes objects (notebooks, libraries, and experiments) into folders, and provides access to data and computational resources such as clusters and jobs.
Create a Databricks workspace
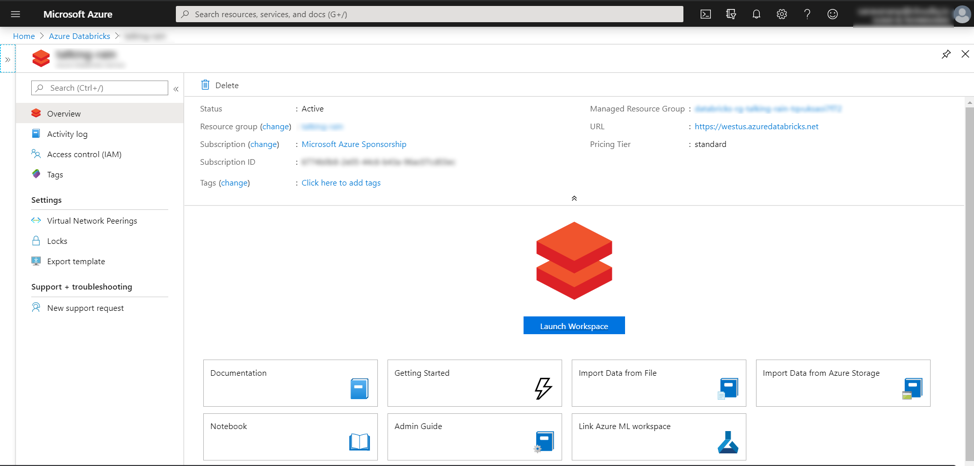
The first step to using Azure Databricks is to create and deploy a Databricks workspace. You can do this in the Azure portal.
- In the Azure portal, select Create a resource > Analytics > Azure Databricks.
- Under Azure Databricks Service, provide the values to create a Databricks workspace.
a. Workspace Name: Provide a name for your workspace.
b. Subscription: Choose the Azure subscription in which to deploy the workspace.
c. Resource Group: Choose the Azure resource group to be used.
d. Location: Select the Azure location near you for deployment.
e. Pricing Tier: Standard or Premium
Once the Azure Databricks service is created, you will get the screen given below. Clicking on the Launch Workspace button will open the workspace in a new tab of the browser.
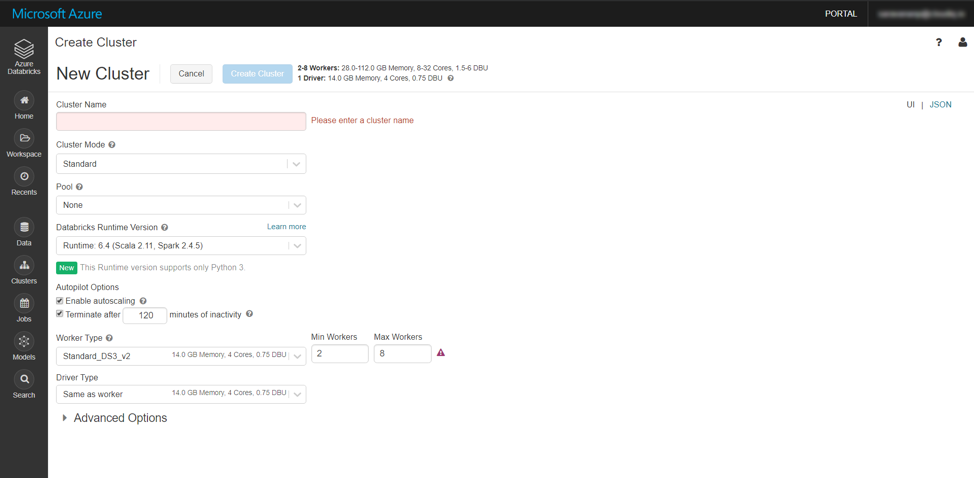
2. Cluster
A Databricks cluster is a set of computation resources and configurations on which we can run data engineering, data science, and data analytics workloads, such as production ETL pipelines, streaming analytics, ad-hoc analytics, and machine learning.
To create a new cluster:
- Select Clusters from the left-hand menu of Databricks’ workspace.
- Select Create Cluster to add a new cluster.
We can select the Scala and Spark versions by selecting the appropriate Databricks Runtime Version while creating the cluster.
3. Notebooks
A notebook is a web-based interface to a document that contains runnable code, visualizations, and narrative text. We can create a new notebook using either the “Create a Blank Notebook” link in the Workspace (or) by selecting a folder in the workspace and then using the Create >> Notebook menu option.
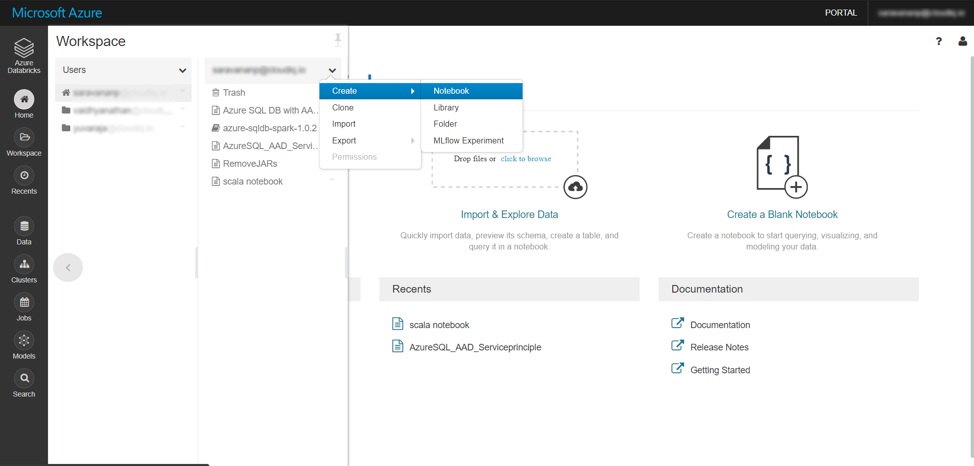
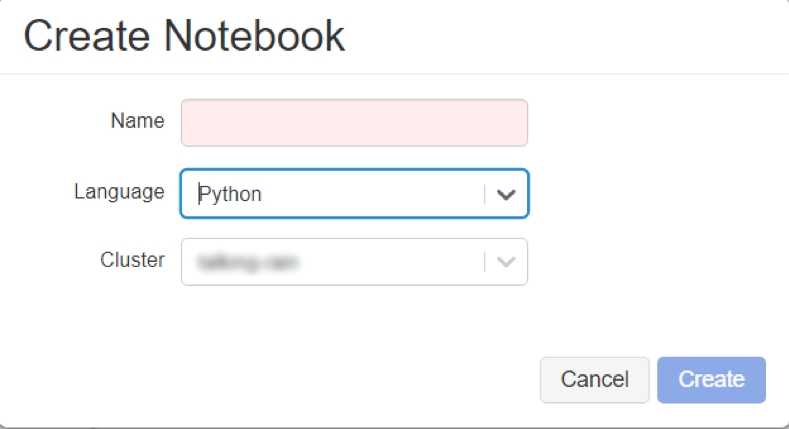
While creating the notebook, we must select a cluster to which the notebook is to be attached and also select a programming language for the notebook – Python, Scala, SQL, and R are the languages supported in Databricks notebooks.
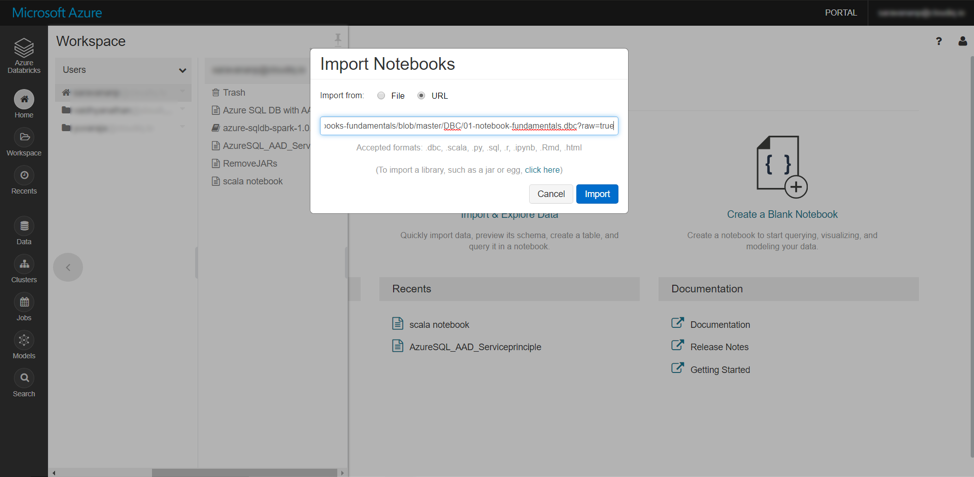
The workspace menu also provides us the option to import a notebook, by uploading a file (or) specifying a file. This is helpful if we want to import (Python / Scala) code developed in another IDE (or) if we must import code from an online source control system like git.
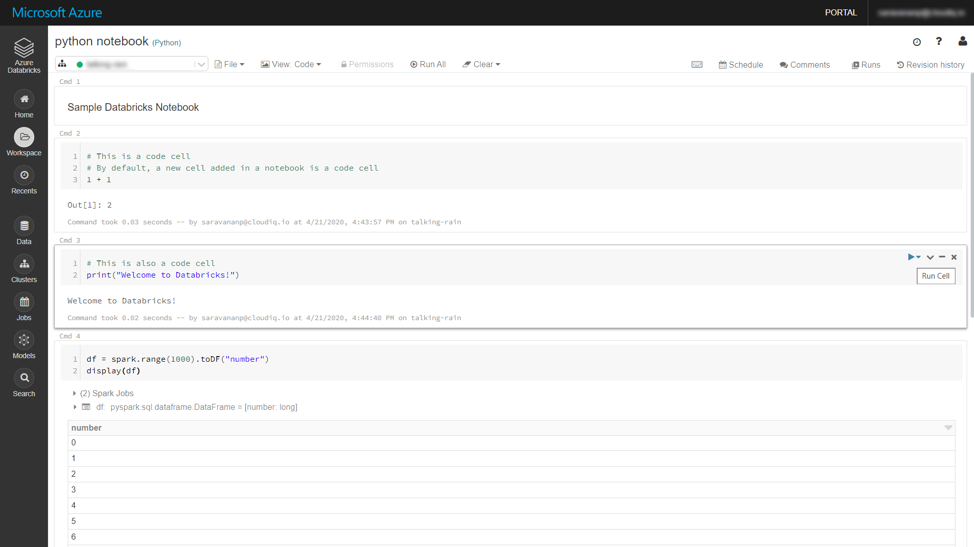
In the below notebook we have python code executed in cells Cmd 2 and Cmd 3; a python spark code executed in Cmd 4. The first cell (Cmd 1) is a Markdown cell. It displays text which has been formatted using markdown language.
Magic commands
Even though the above notebook was created with Language as python, each cell can have code in a different language using a magic command at the beginning of the cell. The markdown cell above has the code below where %md is the magic command:
%md Sample Databricks Notebook
The following provides the list of supported magic commands:
- %python – Allows us to execute Python code in the cell.
- %r – Allows us to execute R code in the cell.
- %scala – Allows us to execute Scala code in the cell.
- %sql – Allows us to execute SQL statements in the cell.
- %sh – Allows us to execute Bash Shell commands and code in the cell.
- %fs – Allows us to execute Databricks Filesystem commands in the cell.
- %md – Allows us to render Markdown syntax as formatted content in the cell.
- %run – Allows us to run another notebook from a cell in the current notebook.
4. Libraries
To make third-party or locally built code available (like .jar files) to notebooks and jobs running on our clusters, we can install a library. Libraries can be written in Python, Java, Scala, and R. We can upload Java, Scala, and Python libraries and point to external packages in PyPI, or Maven.
To install a library on a cluster, select the cluster going through the Clusters option in the left-side menu and then go to the Libraries tab.
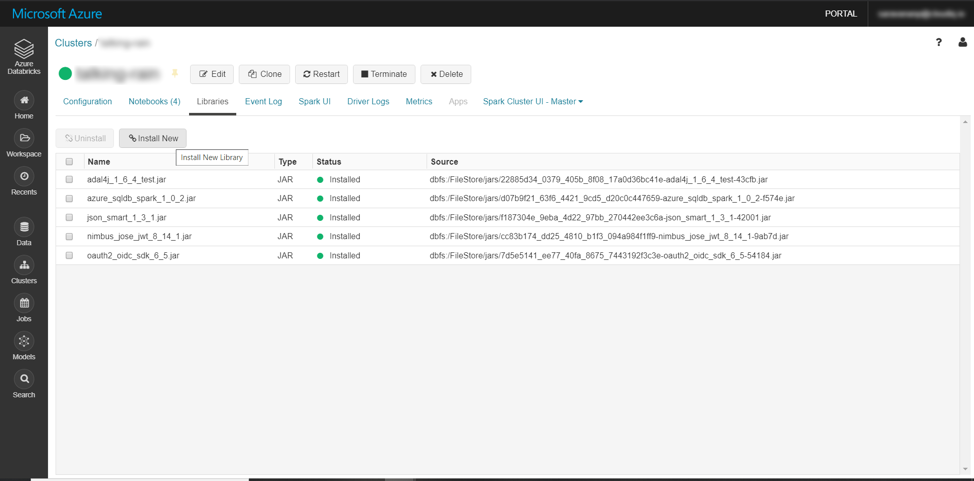
Clicking on the “Install New” option provides us with all the options available for installing a library. We can install the library either uploading it as a Jar file or getting it from a file in DBFS (Data Bricks File System). We can also instruct Databricks to pull the library from Maven or PyPI repository by providing the coordinates.
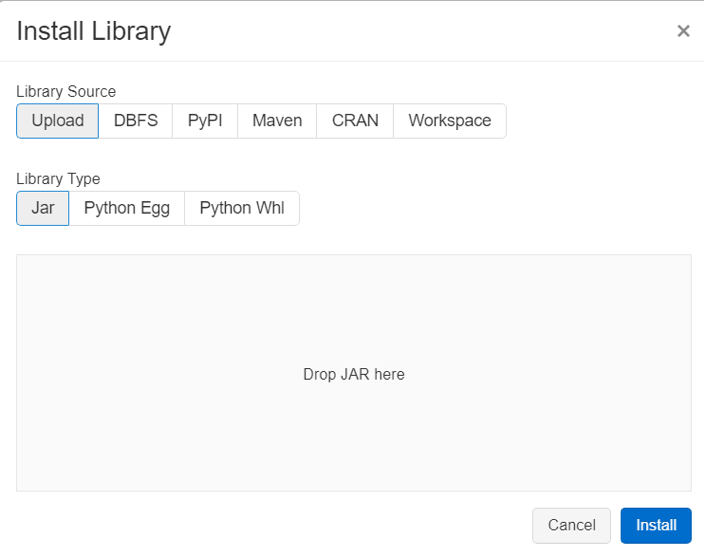
5. Jobs
During code development, notebooks are run interactively in the notebook UI. A job is another way of running a notebook or JAR either immediately or on a scheduled basis.
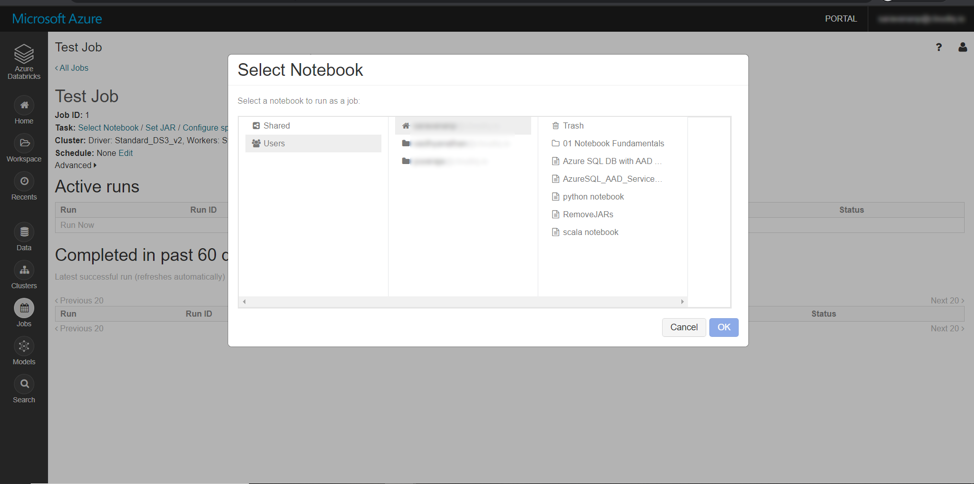
We can create a job by selecting Jobs from the left-side menu and then provide the name of job, notebook to be run, schedule of the job (daily, hourly, etc.)
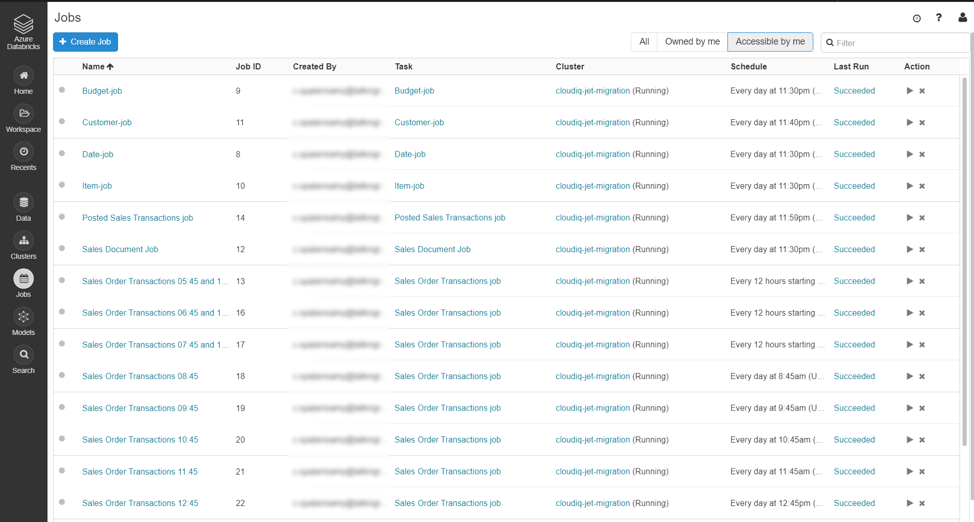
Once the jobs are scheduled, the jobs can be monitored using the same Jobs menu.
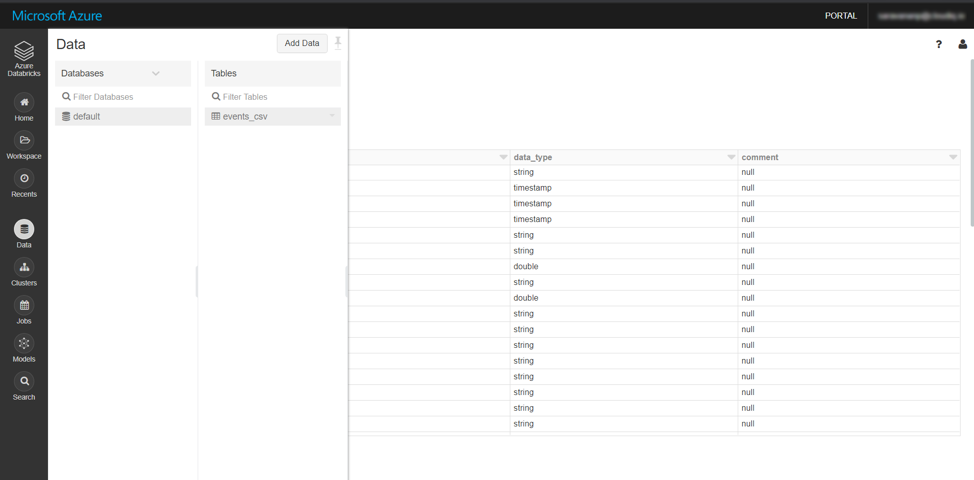
6. Databases and tables
A Databricks database is a collection of tables. A Databricks table is a collection of structured data. Tables are equivalent to Apache Spark DataFrames. We can cache, filter, and perform any operations supported by DataFrames on tables. You can query tables with Spark APIs and Spark SQL.
Databricks provides us the option to create new Tables by uploading CSV files; Databricks can even infer the data type of the columns in the CSV file.
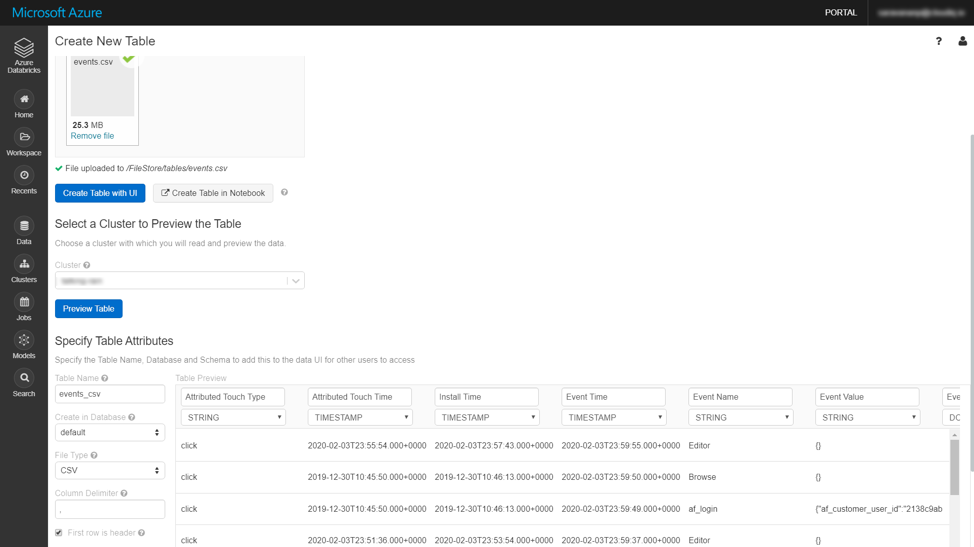
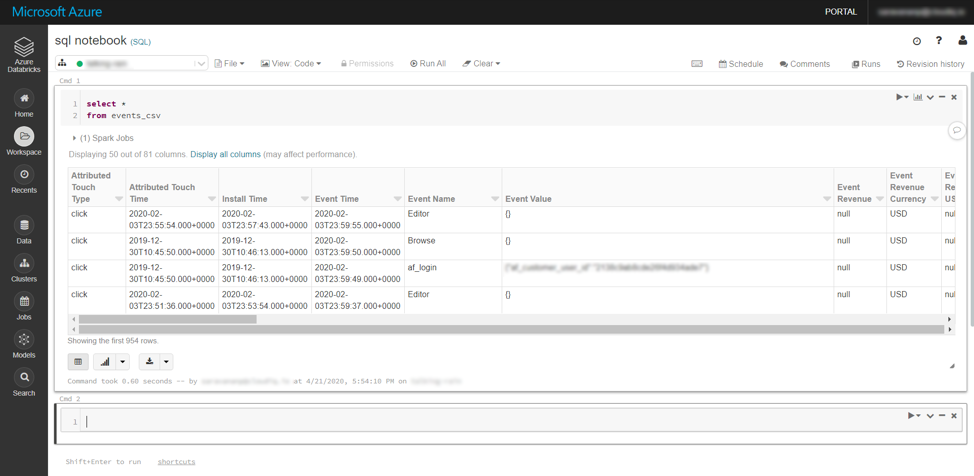
All the databases and tables created either by uploading files (or) through Spark programs can be viewed using the Data menu option in Databricks workspace and these tables can be queried using SQL notebooks.
We hope this article helps you getting started with Azure Databricks. You can now spin up clusters and build quickly in a fully managed Apache Spark environment with the global scale and availability of Azure.
Share this:
CloudIQ is a leading Cloud Consulting and Solutions firm that helps businesses solve today’s problems and plan the enterprise of tomorrow by integrating intelligent cloud solutions. We help you leverage the technologies that make your people more productive, your infrastructure more intelligent, and your business more profitable.
LATEST THINKING
INDIA
Chennai One IT SEZ,
Module No:5-C, Phase ll, 2nd Floor, North Block, Pallavaram-Thoraipakkam 200 ft road, Thoraipakkam, Chennai – 600097
© 2023 CloudIQ Technologies. All rights reserved.